Pandas を使った種実類の栄養成分解析
食品成分データベースから栄養成分を記した CSV ファイル入手し,Pandas を使って散布図の作成やソートなどをおこない,以下の関係を示した.
- 種実類は,エネルギー源を糖として貯蔵するタイプと,脂質として貯蔵するタイプに二分できる
- エネルギー源を脂質として貯蔵するタイプには,脂質と食物繊維とのあいだにトレードオフの関係がある
- n-3 系多価不飽和脂肪酸と α-トコフェロールに限定すると,種実類は,そのどちらかのみを蓄積しているようにみえる
- β-カロテンと α-トコフェロールに限定すると,種実類は,そのどちらかのみを蓄積しているようにみえる
- α-トコフェロール含量を油脂あたりで見ると,単糖当量が乾燥重量の 8 割を超える「ひし」が最大となった
インフォメーション
食品成分データベース
食品の成分については,文部科学省が日本食品標準成分表・資源に関する取組:文部科学省で取りまとめており,日本食品標準成分表・資源に関する取組:文部科学省で Excel 形式と PDF 形式が公開されている.また,「食品成分データベース」としても公開されている.ここでは後者の「食品成分データベース」を利用する.
「Pandas って何?」という人向け情報
Python はプログラミング言語のひとつ,Pandas は Python で使用するライブラリのひとつです.Pandas を使うと,Python プログラム内で表計算ソフトのような処理がおこなえます.
Pandas で作成する二次元テーブルはデータフレーム DataFrame といいます.また,列のことをシリーズ Series ともいいます.
Pandas には,データフレーム,行,列,要素などを処理する多くのメソッドが用意されています.
Pandas の公式ドキュメントは,pandas documentation にあります.
執筆時点での筆者は,ビギナー向けドキュメントを勉強しているレベルです.すなわち,片言の Python を学んだ上で,Getting started:Intro to pandas でおおまかなイメージを把握し,10 minutes to pandas(User Guid の最初のページ)を読んだところです.
自作の Pandas 練習ノート もあります.
目次(ページ内リンク)
データフレームの作成
エネルギー源としての種実類
多価不飽和脂肪酸と抗酸化成分
データフレームの作成
データの入手と前処理
このページで利用したデータは,食品成分データベース から入手した.
食品成分データベースは,食品の成分を論じる際のデファクトスタンダードであると思う.
検索結果は CSV 形式でダウンロード可能である.デフォルトのファイル名は,myData.csv となる.
ダウンロードしたファイルの一例を,5 行めまで示す.
このファイルでは,デフォルトのデータ("廃棄率" から "食塩相当量" まで)以外に,"トリアシルグリセロール当量" その他いつかの成分を追加して検索している.
"食品成分","廃棄率","エネルギー","水分","たんぱく質","脂質","炭水化物","灰分","食塩相当量","トリアシルグリセロール当量","αートコフェロ|ル","脂肪酸総量","単糖当量","n-3系多価不飽和脂肪酸", "重量","削除","単位" ,"%","kcal","g","g","g","g","g","g","g","mg","g","g","g","g" "種実類/アーモンド/乾","0","609","4.7","19.6","51.8","20.9","3.0","0","51.9","30.0","49.68","5.5","0.01",100, "種実類/アーモンド/フライ/味付け","0","626","1.8","21.3","55.7","17.9","3.2","0.3","53.2","22.0","50.86","4.9","0.03",100, "種実類/あさ/乾","0","450","4.6","29.9","28.3","31.7","5.5","0","27.3","1.8","26.07","2.6","4.74",100,
ダウンロードされるファイル,はもちろん Pandas 専用ではない.
そのままでは使いにくい要素が含まれているので,多少の整形作業が必要となる.
例えば,
- 2 行めは単位(100g あたり重量など)となっている.そのままにしておくと,種実類の一種として計算されることになる
- 最終行は合計値である.このページでは使わない
- ある成分が検出限界以下の場合,CSV ファイルには空要素(,,)として記される.これは,read_csv() で開くと NaN(Not a Number) と解釈される
- 痕跡量は,Tr と文字列で記されているので計算できない.例えば,0 に書き換える
- 推定値は例えば '(0.123) と記述されており,文字列として処理されてしまう.このページでは,0.123 に書き換えて「確定値」として処理する
なお,未測定の場合,"-" と記される.
このぺージでは,「このデータは利用できない」という記号として使っている.
これらの処理はエディタや表計算ソフトでも可能である.
しかし,類似した作業を繰り返すなら,処理するためのコードを書いておく方がいいと思う.
CSV ファイルからデータフレームを作成
CSV ファイルからデータフレームを作成するには,pandas.read_csv() というメソッドを利用する.
下にサンプルコードを記してみる.データの前処理は省略した.
read_csv() メソッドのオプション引数はたくさんあるが,ここではファイル名とインデックス行のみを設定している.
データフレームが作成できたことは,pandas.head() を呼び出して確認している.
ファイル名を main.py とする.
import pandas as pd # Pandas ライブラリを pd としてインポート.pd にするのは本家ドキュメントで推奨されている慣例
df = pd.read_csv("./myData.csv", index_col=0) # pandas.read_csv() の戻り値がデータフレームである
#必要に応じて,ここにデータの前処理をコーディングする
print(df.head()) # 作成したデータフレームの冒頭部分を出力.デフォルトは 5 行
main.py を実行するには,端末で myData.csv を置いたディレクトリに移動し,
$ python3 main.py
とすればよい.
下がその実行結果である.
head() の出力から,行と列のラベルが設定できたことが判る.
前処理していないので,単位が記された行が含まれていたり,NaN が要素として含まれていたりする.このままでは計算できない.
廃棄率 エネルギー 水分 たんぱく質 脂質 炭水化物 灰分 食塩相当量 トリアシルグリセロール当量 αートコフェロ|ル 脂肪酸総量 単糖当量 n-3系多価不飽和脂肪酸 重量 削除 単位
食品成分
NaN % kcal g g g g g g g mg g g g g NaN NaN
種実類/アーモンド/乾 0 609 4.7 19.6 51.8 20.9 3.0 0 51.9 30.0 49.68 5.5 0.01 100 NaN NaN
種実類/アーモンド/フライ/味付け 0 626 1.8 21.3 55.7 17.9 3.2 0.3 53.2 22.0 50.86 4.9 0.03 100 NaN NaN
種実類/あさ/乾 0 450 4.6 29.9 28.3 31.7 5.5 0 27.3 1.8 26.07 2.6 4.74 100 NaN NaN
種実類/えごま/乾 0 523 5.6 17.7 43.4 29.4 3.9 0 40.6 1.3 38.79 2.5 23.70 100 NaN NaN
エネルギー源としての種実類
種実類を「胚のためにエネルギーを蓄積する器官」とみなすと,脂質や炭水化物が多いと予測できる.予測というより一般常識であろう.
では,脂質と炭水化物とのあいだにはどのような関係があるのであろうか? 単純なトレードオフであろうか?
解析を試みた.
単糖当量と脂肪酸総量の散布図
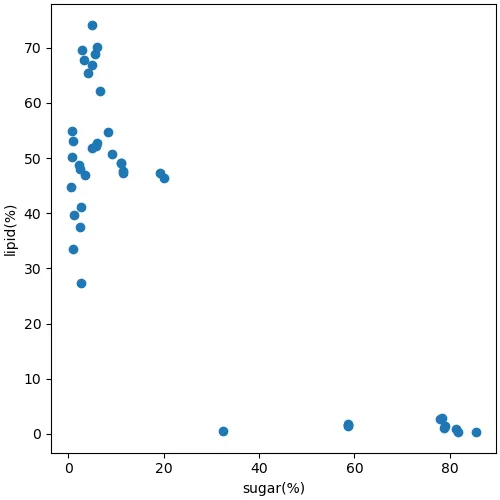
まず,直接的なエネルギー源となりそうな,単糖当量と脂肪酸総量との関係を調べてみた.
植物は,エネルギーの貯蔵形態として双方を利用できるであろうから,負の相関関係が見られると予想した.
この予想を検証するために,単糖当量と脂肪酸総量を含むめた検索をおこない,CSV ファイルを入手した.
このファイルを使い,乾燥重量あたりの単糖当量と脂肪酸総量を計算し,散布図を描いた.
Pandas の API リファレンスを見ると,Pandas.DataFrame クラスには plot() というメソッドがある.散布図を描くにはこれを使う.
plot() の戻り値は matplotlib.axes.Axes というクラスのインスタンスである.
matplotlib.axes.Axes クラスについては,matplotlib.axes.Axes の API リファレンスを読めばよい.
このように API リファレンスを参照しつつ,下のコードを作成した.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#CSV ファイルのオープン
df = pd.read_csv("myData.csv",index_col="食品成分")
#データの前処理用コードは省略
#前処理して作成したデータフレームを df2 とする
#乾燥重量あたりの単糖当量と脂肪酸総量を計算
df2['dry'] = 100 - df2["水分"]
df2["sugar"] = (df2["単糖当量"] / df2['dry']) * 100
df2['lipid'] = (df2['脂肪酸総量'] / df2['dry']) * 100
#散布図を描く
fig, ax = plt.subplots(figsize=(5,5),layout='constrained')
ax.scatter('sugar','lipid',data=df2)
ax.set_xlabel('sugar(%)')
ax.set_ylabel('lipid(%)')
plt.show()
予想したような散布図にはならなかった.
負の相関関係と言えないこともないのであろうが,「種実類は,エネルギー源を糖として貯蔵するタイプと,脂質として貯蔵するタイプに二分できるようだ」と表現したほうがよさそうである.
糖と脂質の両方をエネルギー源として貯蔵するような種実は進化しにくいということであろうか.
食物繊維と脂肪酸総量の散布図
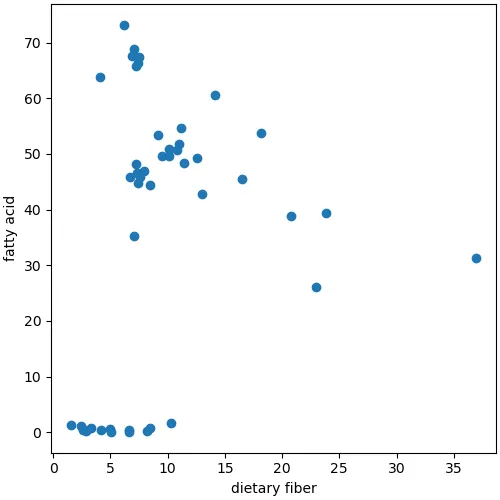
光合成によって産生された糖は,食物繊維の合成にも利用される.食物繊維はヒトには利用できないので,単糖当量には含まれない.
単糖当量が少ない種実類(上のサブセクションで作成した,単糖当量と脂肪酸総量の散布図の左端にかたまっているグループ)は,食物繊維を多く含むのではないだろうか?
この予想を検討するために,食物繊維総量と脂肪酸総量のデータを含む CSV ファイルをダウンロードし,解析してみた.
上とほぼ同じなので,脂肪酸総量が少ないグループを出力するコードの部分のみ記す.
予備実験で,脂肪酸総量が少ないグループが見いだしていたたためである.
#脂肪酸総量が少ないグループを,食物繊維総量が多い順にソートして出力
df3 = df2[df2['脂肪酸総量'] < 10]
df4 = df3.sort_values(by=['食物繊維総量'],ascending=False)
print('脂肪酸総量が 10% である種実類の食物繊維総量')
print(df4['食物繊維総量'])
散布図を見ると,脂肪酸総量が少ないグループが横軸付近に分布している.これらは食物繊維も少ない.
これらを除外すれば,食物繊維総量と脂肪酸総量とのあいだには負の相関関係がありそうに見える.
出力された脂肪酸総量が少ないグループを下に記す.
脂肪酸総量が 10% である種実類の食物繊維総量/乾燥重量 (ひし類)/とうびし/生 22.969188 (くり類)/日本ぐり/ゆで 15.865385 とち/蒸し 15.714286 (くり類)/中国ぐり/甘ぐり 15.287770 (ひし類)/とうびし/ゆで 14.782609 はす/成熟/ゆで 14.749263 はす/成熟/乾 11.599099 はす/未熟/生 11.555556 (くり類)/日本ぐり/生 10.194175 (ひし類)/ひし/生 6.016598 ぎんなん/ゆで 5.568445 しい/生 5.263158 (くり類)/日本ぐり/甘露煮 4.729730 ぎんなん/生 3.755869 Name: fiber, dtype: float64
食物繊維と脂肪酸総量のランキング
コードを多少変更して,食物繊維/乾燥重量 や 脂肪酸総量/乾燥重量 が大きい種実を出力してみた.
食物繊維/乾燥重量が大きい種実トップ 5 チアシード/乾 39.465241 あさ/乾 24.109015 あまに/いり 23.991935 (ひし類)/とうびし/生 22.969188 えごま/乾 22.033898 Name: fiber, dtype: float64 脂肪酸総量/乾燥重量が大きい種実トップ 5 マカダミアナッツ/いり/味付け 74.214792 ペカン/フライ/味付け 70.122324 くるみ/いり 69.566563 まつ/いり 68.837920 ブラジルナッツ/フライ/味付け 67.767490 Name: lipid, dtype: float64
エネルギー源としての種実類セクションのとりあえずの解釈
以上の解析から,次のように考える.
種実類は基本的に,光合成によって得られた糖類を単糖当量(デンプンや少糖類)として貯蔵する.
別経路として,脂質として貯蔵することもできる.ただしこの場合は,脂質と食物繊維(セルロース)のあいだでトレードオフの関係が成立している.
どの貯蔵方法を取るかは,その種実の散布形式とも関わるのであろう.
多価不飽和脂肪酸と抗酸化成分
n-3 系多価不飽和脂肪酸と α-トコフェロール
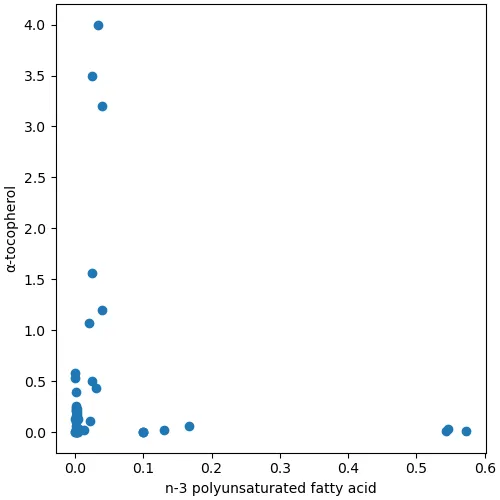
n-3 系多価不飽和脂肪酸はいわゆる必須脂肪酸であり,言うまでもないが脂質の構成成分である.空気中では酸化されやすい(不飽和度によって酸化されやすさが異なる).
α-トコフェロールは,抗酸化活性を有する脂溶性ビタミンである.
ヒトの栄養学と植物の栄養学を区別せず,また他の多価不飽和脂肪酸や他の抗酸化活性を無視した議論になるが,n-3 系多価不飽和脂肪酸含量と α-トコフェロール含量のあいだには正の相関関係があるかもしれない(と思った).
これを調べるには,「エネルギー源としての種実類」セクションと同じ方法を使えばよい.
下にソースコードを記す.
「エネルギー源としての種実類」セクションで散布図を作成したときとほぼ同じなので,計算の部分のみ記す.
n-3 系多価不飽和脂肪酸と α-トコフェロール含量は,脂質含量あたりの換算値としている.
なお,"αートコフェロ|ル" となっているのは,ダウンロードした CSV ファイルがそうなっているのをそのまま使っているせいである.
#乾燥重量あたりの単糖当量と脂肪酸総量を計算
df2["n3"] = (df2["n-3系多価不飽和脂肪酸"] / df2['脂質'])
df2['toc'] = (df2['αートコフェロ|ル'] / df2['脂質'])
散布図を見ると,両成分には正の相関関係はないと言えそうである.
α-トコフェロールと n-3 系多価不飽和脂肪酸の両方を多く含むナッツはない,と言ってよさそうだ.
これらに限定すると,種実類は,そのどちらかを優先して蓄積しているようにみえてしまう.
n-3 系多価不飽和脂肪酸と α-トコフェロールの含量ランキング
ソースコードを記す.「エネルギー源としての種実類」セクションでランキングを調べたときとほぼ同じである.
ただし,種実重量あたりの含量と油脂あたりの含量の両方を計算した.
#ソート
df2.sort_values(by=['n-3系多価不飽和脂肪酸'],ascending=False,inplace=True)
print("n-3 系多価不飽和脂肪酸/種実 のトップ 5")
print(df2['n-3系多価不飽和脂肪酸'].head())
print()
df2.sort_values(by=['n3'],ascending=False,inplace=True)
print("n-3 系多価不飽和脂肪酸/油脂 のトップ 5")
print(df2['n3'].head())
print()
df2.sort_values(by=['αートコフェロ|ル'],ascending=False,inplace=True)
print("α-トコフェロール/種実 のトップ 5")
print(df2['αートコフェロ|ル'].head())
print()
df2.sort_values(by=['toc'],ascending=False,inplace=True)
print("α-トコフェロール/油脂 のトップ 5")
print(df2['toc'].head())
下が出力である.
n-3 系多価不飽和脂肪酸/種実 のトップ 5 えごま/乾 23.70 あまに/いり 23.50 チアシード/乾 19.43 くるみ/いり 8.96 あさ/乾 4.74 Name: n-3系多価不飽和脂肪酸, dtype: float64 n-3 系多価不飽和脂肪酸/油脂 のトップ 5 チアシード/乾 0.573156 えごま/乾 0.546083 あまに/いり 0.542725 あさ/乾 0.167491 くるみ/いり 0.130233 Name: n3, dtype: float64 α-トコフェロール/種実 のトップ 5 アーモンド/乾 30.0 アーモンド/いり/無塩 29.0 アーモンド/フライ/味付け 22.0 ヘーゼルナッツ/フライ/味付け 18.0 ひまわり/フライ/味付け 12.0 Name: αートコフェロ|ル, dtype: float64 α-トコフェロール/油脂 のトップ 5 (ひし類)/とうびし/ゆで 4.0000 (ひし類)/とうびし/生 3.5000 (ひし類)/ひし/生 3.2000 ぎんなん/生 1.5625 はす/未熟/生 1.2000 Name: toc, dtype: float64
種実の種類で述べると,α-トコフェロールは,「アーモンド」や「ヘーゼルナッツ」に多く含まれている.n-3 系多価不飽和脂肪酸を多く含む種実は,「えごま」,「あまに」などである.
ちなみに筆者は,献立にアーモンドとクルミを組み入れている.
α-トコフェロール含量を油脂あたりで見ると,単糖当量が乾燥重量の 8割を超える「ひし」が最大となった.
説明を思いつかない.「ひし」の油脂分画は酸化ストレスにさらされている,とでもいうのであろうか.
多価不飽和脂肪酸と α-トコフェロール,β-カロテン
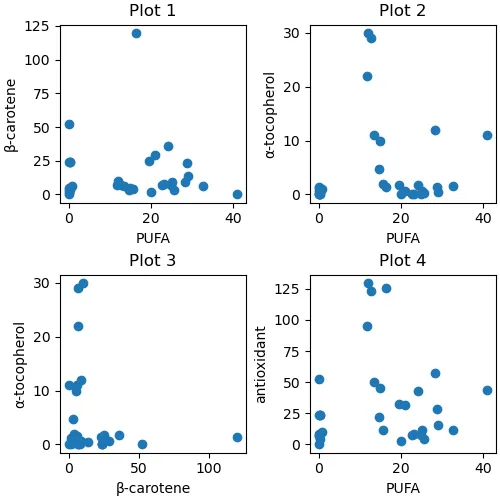
もう少し成分の範囲を広げてみる.
このサブセクションでは抗酸化成分として β-カロテンも加える.また,脂肪酸は,n-3 系多価不飽和脂肪酸ではなく多価不飽和脂肪酸(PUFA)とした.
データをダウンロードして散布図を描いてみた.タイトルはグラフの上に記されている.
Plot 4 の抗酸化成分の線形結合にはあまり意味はない.量的な調整をおこなってみただけである.
- Plot 1:多価不飽和脂肪酸 vs β-カロテン
- Plot 2:多価不飽和脂肪酸 vs α-トコフェロール
- Plot 3:β-カロテン vs α-トコフェロール
- Plot 4:多価不飽和脂肪酸 vs 抗酸化成分(ここでは β-カロテン + α-トコフェロール * 4)
これまでに記した散布図のコードを多少変更すると,散布図を並べた画像を作成できる.
fig, axs = plt.subplots(2,2,figsize=(5,5),layout='constrained')
axs[0,0].scatter('多価不飽和脂肪酸','βーカロテン',data=df2)
axs[0,0].set_xlabel('PUFA')
axs[0,0].set_ylabel('β-carotene')
axs[0,0].set_title('Plot 1')
axs[0,1].scatter('多価不飽和脂肪酸','αートコフェロ|ル',data=df2)
axs[0,1].set_xlabel('PUFA')
axs[0,1].set_ylabel('α-tocopherol')
axs[0,1].set_title('Plot 2')
axs[1,0].scatter('βーカロテン','αートコフェロ|ル',data=df2)
axs[1,0].set_xlabel('β-carotene')
axs[1,0].set_ylabel('α-tocopherol')
axs[1,0].set_title('Plot 3')
axs[1,1].scatter('多価不飽和脂肪酸','antioxidant',data=df2)
axs[1,1].set_xlabel('PUFA')
axs[1,1].set_ylabel('antioxidant')
axs[1,1].set_title('Plot 4')
plt.show()
多価不飽和脂肪酸と抗酸化成分とのあいだに明瞭な関係は見いだせなかった.
抗酸化成分と脂肪酸画分
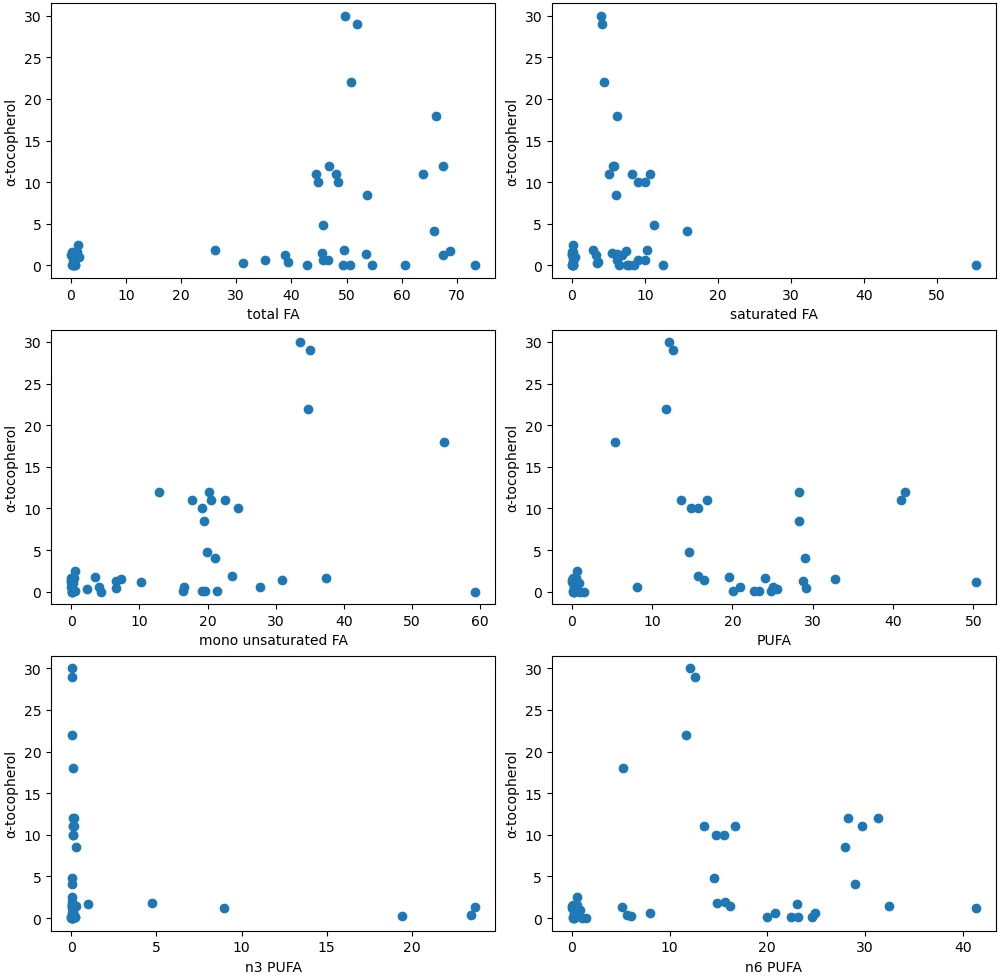
さらに成分の範囲を広げてみた.
縦軸にα-カロテン,β-カロテン,β-クリプトキサンチン,α-トコフェロール,β-トコフェロール,γ-トコフェロール,δ-トコフェロールをとり,
それぞれについて横軸に脂肪酸総量,飽和脂肪酸,一価不飽和脂肪酸,多価不飽和脂肪酸,n-3系多価不飽和脂肪酸,n-6系多価不飽和脂肪酸をとり,
散布図を描いてみた.
図は,縦軸に α-トコフェロールをとった場合の散布図である.
α-トコフェロールと n-3系多価不飽和脂肪酸の組み合わせ(左下の散布図)のみ,一方が蓄積されているようにみえる.
このような関係は他の組み合わせでは見いだせなかった.
注.
α-カロテンも一見同様のパタンを示したが,これは「くり」での含量が大きいことが原因であった.
データには,
種実類/(くり類)/日本ぐり/生,種実類/(くり類)/日本ぐり/ゆで,種実類/(くり類)/日本ぐり/甘露煮,種実類/(くり類)/中国ぐり/甘ぐり
の 4 種類の値が含まれており,他の種実類は α-カロテン含量が検出限界以下か桁違いに小さい.
このセクションのまとめ
このセクションでは,種実類の抗酸化成分と多価不飽和脂肪酸について解析し,下の結果を得た.
- α-トコフェロールと n-3 系多価不飽和脂肪酸のどちらか一方が蓄積されているようにみえる
- β-カロテンと α-トコフェロールのどちらか一方が蓄積されているようにみえる
- β-カロテンおよび α-トコフェロールと多価不飽和脂肪酸とのあいだには,明瞭な関係は見いだせなかった